A while back, I wrote a toy polymorphic database engine in Rust. It’s purpose was to enable
CRUD operations on document and relational row and columnar formats, in one DB.
I wrote the paging system, interpreter, query executor, and client.
But it wasn’t very efficient. I can’t remember just how bad it was but going by the popular saying
“If you can optimize something 1.5x, thats good. If you can optimize it by 100x, you must be doing something stupid”.
I was definitely doing making several inefficient choices.
Identifying Initial Inefficiencies
The first major issue was in the scanner, which was extremely inefficient. The peek operations were O(n) instead
of O(1), due to my misuse of the chars().nth() method. This made the overall time complexity of
the scanner approximately O(n²).
fn peek(&self) -> char {
if self.is_at_end() {
'\0'
} else {
*** self.source.chars().nth(self.current).unwrap() ***
/// Improved version
self.source[self.current..].chars().next().unwrap_or('\0')
}
}
fn peek_next(&self) -> char {
if self.current + 1 >= self.source.len() {
'\0'
} else {
*** self.source.chars().nth(self.current + 1).unwrap() ***
/// Improved version
self.source[self.current + 1..].chars().next().unwrap_or('\0')
}
}
With that fixed, the second thing was actually performance in stress testing. See, given my interest in software performance, I decided to profile how long it would take my engine to handle large-scale operations.
I started off with tests on thousand row insertions on relational and document row formats using my insert and insertMany operations.
#[test]
fn test_thousand_rows() {
let seq1 = "
dbs.create_db('test_db');
dbs.create_table('test_db' ,'test_rtable', 'RELATIONAL', 'ROW', '{
'name': 'string(50)',
'balance': ['numeric', true],
'pob': 'string',
'active': 'boolean'
}');
";
let seq2 = "
dbs.insert('test_db', 'test_rtable', '{
'name': 'Jane Smith',
'balance': '2502034304.2332',
'pob': 'London',
'active': true
}');
dbs.insert('test_db', 'test_rtable', '{
'name': 'John Doe',
'balance': '450.2332',
'pob': 'New York',
'active': false
}');
";
let seq3 = "
let y = dbs.test_db.test_rtable.offset(0);
y.limit(500);
";
let mut dbms = DBMS::new();
time_it!( "Running everything ", {
time_it!( "Creating the database: ", {handle_query(seq1.to_string(), &mut dbms) });
time_it!("Running the insert 1000 times: ", {
for _ in 0..1000 {
handle_query(seq2.to_string(), &mut dbms);
}
});
time_it!("Fetching some row results: ", { handle_query(seq3.to_string(), &mut dbms) } );
// time_it!("Fetching some row results: ", {println!("{:?}", handle_query(seq3.to_string(), &mut dbms) )} );
});
}
This test took quite a while in debug mode.
Creating the database: : 37.14425ms
Running the insert 1000 times: : 51.252572333s
Fetching some row results: : 16.399834ms
Running everything : 51.306926917s
test tests::test_thousand_rows ... ok
I ran similar tests for document row insertions and observed comparable performance. For brevity in this post, I won’t detail them separately, as the optimizations applied similarly across formats.
However, running the test in release build showed significant improvement, taking only about 3.4 seconds.
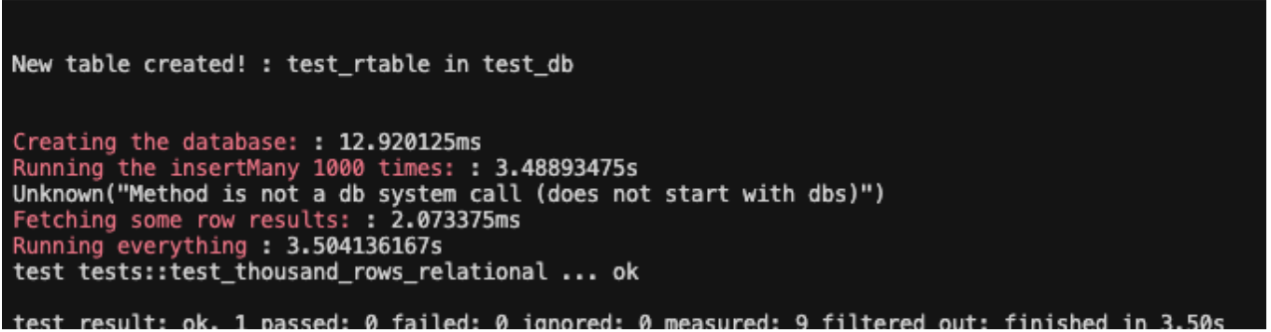
I then generated a flamegraph for the test to start taking a deeper look at what my perf bottlenecks could be.
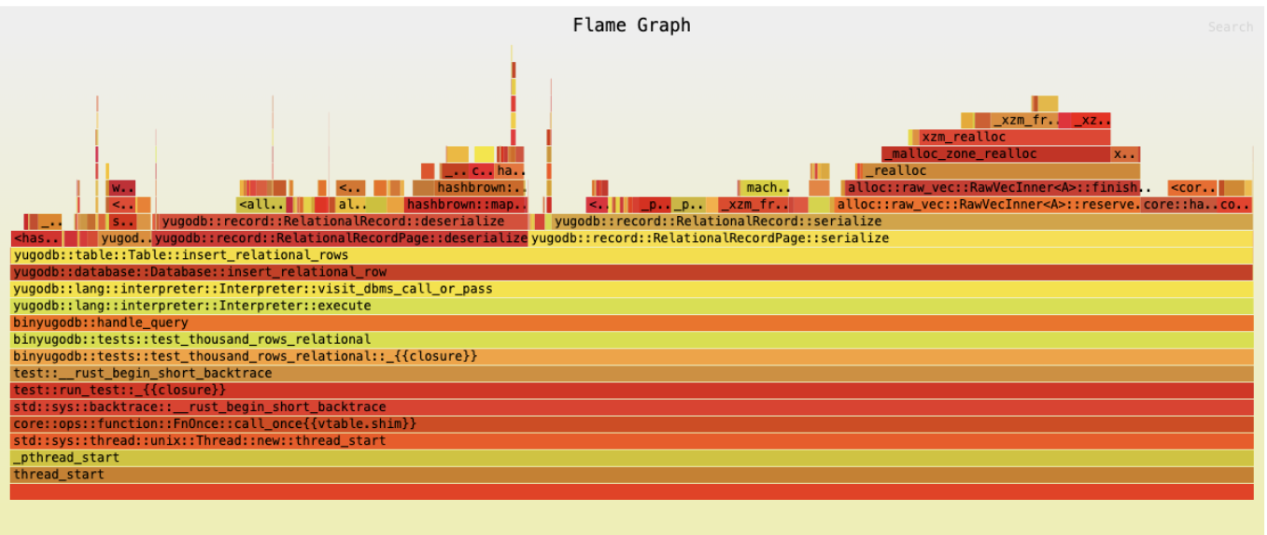
The main hotspots revealed that we were deserializing a page every time we inserted a single row. There are several ways to optimize this, such as storing page offsets and inserting only the serialized content for the new row without full deserialization. I’ll cover that approach in a future blog post.
I also experimented with some simpler optimizations, though they had minimal impact:
- Preallocated the vector size based on the schema and byte length
- Parallelize the deserialize operation based on known offsets
Another bottleneck was flushing the page after every insert. While this is a strict requirement in some production databases for durability, I’ll leave optimizations around batch flushing for later discussion.
Since my focus was on a billion rows, and knowing this bottleneck was for a single insertion, it only made sense for me to shift my focus to my existing insertMany operation, and try to batch a large number of inserts at once.
From now we’ll be taking M = number of records per insertMany operation N = number of insertMany calls made
and be using the convention MxN when talking about batch inserts.
As suspected, the insertMany operation performed better, taking 1 second to insert 10x100 rows. My next attempt was to see how well insertMany could scale, and I did this by attempting a 100x100 inseration. It would turn out I had another bug in my engine, which was that I was creating new pages for most row inserts in an insertMany operation. As you can imagine this balloned my database quite a lot, to even 90GB for this simple test. The issue was due to a value in a condition I failed to update.
pub fn insert_relational_rows(&mut self, rows: Vec<RelationalRecord>) -> Result<()> {
//TODO: what is this about?
// let id = match row.id {
// Some(x) => x.clone(),
// None => self.curr_row_id + 1,
// };
// unimplemented!()
if let Ok(mut pager) = Rc::clone(&self.pager).try_borrow_mut() {
let id = self.curr_row_id;
let schema = match &self.schema {
Schema::Relational(x) => x.clone(),
_ => panic!("Unsupported schema type for relational record"),
};
let curr_page = pager.get_page_or_force(self.curr_page_id)?;
let mut relational_page = match RelationalRecordPage::deserialize(
&(*curr_page).borrow_mut().read_all(),
&schema,
) {
Ok(page) => page,
Err(_) => RelationalRecordPage::new(),
};
let mut i = 0;
let mut start_ser_size = relational_page.serialize(&schema).len();
let mut new_record_size = rows[i].serialize(&schema).len();
//err if the first value is too large to fit in a page
let new_data = rows[0].serialize(&schema);
if new_data.len() > PAGE_SIZE_BYTES {
return Err(Error::Unknown(
"Document size too large to be written to page".to_string(),
));
}
while i < rows.len() && start_ser_size + new_record_size < PAGE_SIZE_BYTES {
relational_page.add_record(rows[i].clone(), self.curr_row_id + i);
start_ser_size += new_record_size;
i+=1;
if i < rows.len(){
new_record_size = rows[i].serialize(&schema).len();
}
}
(*curr_page)
.borrow_mut()
.write_all(relational_page.serialize(&schema));
(id..id+i).for_each(|idx | {
self.default_index
.insert(idx.clone(), (self.curr_page_id, idx.clone() as u8, 0));
});
pager.flush_page(&(*curr_page).borrow_mut())?;
// self.curr_row_id += i;
// persist the remaining rows
let mut prev = i;
while i < rows.len() {
//create a new page
let new_page = pager.create_new_page()?;
let mut new_relational_page = RelationalRecordPage::new();
*** let mut start_ser_size = relational_page.serialize(&schema).len(); ***
let mut new_record_size = rows[i].serialize(&schema).len();
while i < rows.len() && start_ser_size + new_record_size < PAGE_SIZE_BYTES {
new_relational_page.add_record(rows[i].clone(), self.curr_row_id + i);
start_ser_size += new_record_size;
i+=1;
if i < rows.len(){
new_record_size = rows[i].serialize(&schema).len();
}
}
new_page.write_all(new_relational_page.serialize(&schema));
self.curr_page_id += 1;
self.page_index.insert(new_page.index, self.curr_page_id);
(id + prev.. id+i).for_each(|idx | {
self.default_index
.insert(idx.clone(), (self.curr_page_id, idx.clone() as u8, 0));
});
pager.flush_page(&new_page)?;
prev = i;
}
self.curr_row_id += i;
Ok(())
} else {
return Err(Error::Unknown(
"Failed to borrow cache mutably from here".to_string(),
));
}
}
Fixing that though, things returned to normal. I was able to perform a 10000x100 insertion in 6.5s (155k rows/sec) and a 10000x1000 insertion in 71s which was pretty amazing. This performance was consistent for document rows as well.
But from these it was obvious that a billion rows would take quite a while. I could’ve chimped out a bit and just scaled down the number of raw insert calls, but I decided it would only be fair to leave as is.
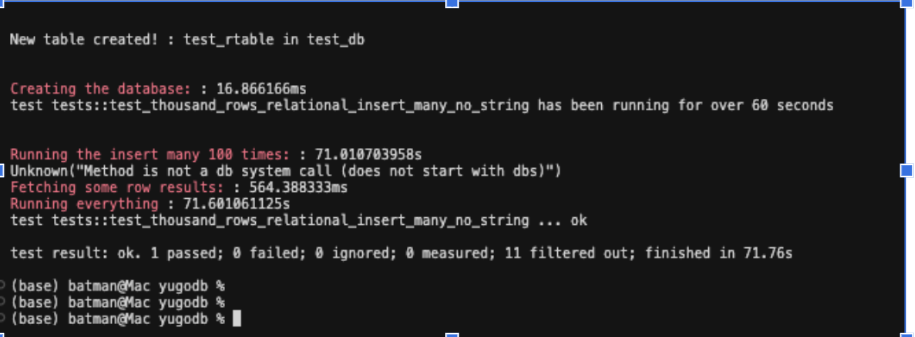
In the next part, I’ll dive deeper into advanced optimizations like offset-based inserts without full deserialization and potential batch flushing strategies. Thanks for reading!